Cloud Environment¶
Identity and IAM Hierarchy¶
At the foundation of your Google Cloud Platform (GCP) organization is a relationship with your trusted identity provider. Commonly, this is a Gsuite domain or a Cloud Identity installation. It's the basis of trust for how users and groups are managed throughout the GCP environments. It's where you audit logins/logouts, enforce MFA and session duration, and more.
It's important to understand that in a GCP organization, where a user is granted permissions is just as important as what permissions are granted. For example, granting a user or service account a binding to an IAM role for Storage Admin at the project level allows that account to have all those permissions for all Google Cloud Storage (GCS) buckets in that project.
Consider a somewhat realistic scenario: That project has GCS buckets for storing audit logs, VPC flow logs, and firewall logs. The security team is given Storage Admin permissions to manage these. Also in that same project, a development team wants to store some data used by their application. They too, get assigned Storage Admin permissions to that project. There are a few problems:
- Unless the security team is the one that made the IAM permissions assignment, they might not be aware of the exposure of their security log and event data. This jeopardizes the integrity of the information if needed for incident response and guaranteeing chain of custody.
- The development team now has access to this sensitive security information. Even though they may never access it or need to, this violates the principle of least privilege.
- Any time a new GCS bucket is added to this
project, both teams will have access to it automatically. This can often be undesired behavior and tricky to untangle.
Things get even more interesting when you consider a group of projects organized into a GCP Folder. Permissions granted to a Folder "trickle down" to the Folders and projects inside them. Because permissions are additive, a descendent project can't block or override those permissions. Therefore, careful consideration must be given to access granted at each level, and special attention is needed for IAM roles bound to users/groups/service accounts at the Folder or Organization levels. Some examples to consider:
- If a user is assigned the primitive role
Ownerat the Organization level, they will beOwnerin every singleprojectin the entire organization. The risk of compromise of those specific credentials (and by extension, that user's primary computing devices) is immediately increased to undesired levels. - Granting
Viewerat the Organization level allows reading all GCS buckets, all StackDriver logs, and viewing the configurations of most resources. In many cases, sensitive data is found in any or all of those places that can be used to escalate privileges.
IAM "Overcrowding"
The IAM page in the GCP Console tends to get "crowded" and harder to visually reason about when there are lots of individual bindings. Each IAM Role binding increases the cognitive load when reviewing permissions. Over time, this can get unwieldy and difficult to consolidate once systems and services are running in production.
Best Practices¶
- Use a single Identity Provider - If all users and groups are originating from a single domain and are managed centrally, maintaining the proper IAM permissions throughout the GCP Organization is greatly simplified.
- Ensure all accounts use Multi-Factor Authentication (MFA) - Protecting the theft and misuse of GCP account credentials is the first and most important step to protecting your GCP infrastructure. If a set of credentials is stolen or a laptop lost, the window for those credentials to be valid is greatly reduced.
- Consolidate Users into Groups - Instead of granting individual users access, consider using a group, placing that user in that group, and granting access to the group. This way, if that person leaves the organization, it doesn't leave orphaned/unused accounts clogging up the IAM permissions listings that have to be manually removed using gcloud/UI. Also, when replacing that person who left, it's a simpler process of just adding the new person(s) to the same groups. No gcloud/UI changes are then necessary.
- Follow the Principle of Least Privilege - Take care when granting access Project-wide and even greater care when granting access at the Folder and Organization levels. There are often unintended consequences of over-granting permissions. Additionally, it's much harder to safely remove that binding as time goes on because inherited permissions might be required in a descendent project.
Resources¶
- Creating and Managing GCP Organizations
- GCP Resource Hierarchy
- GSuite Security
- Cloud Identity Overview
- Cloud IAM Overview
Organization, Folder, and Project Structure¶
Resource hierarchy decisions made early on in your GCP journey tend to have a "inertia". Meaning, once they are configured a certain way, they become entrenched and harder to change as time goes on. If configured well, they can reduce administrative and security toil in managing resources and access to those resources in a clean, manageable way. If configured sub-optimally, you might feel like making administrative changes is overly complex and burdensome. Often, these decisions are often made in haste during design and implementation efforts "just to get things working". It might seem that there is pressure to get things perfect from the outset, but there is some level of built-in flexibility that you can take advantage of -- provided certain steps are taken.
The two components of the GCP resource hierarchy that are trickiest to change are the organization and the non-empty project. The organization is the root of all resources, so it establishes the hierarchy. Projects cannot be renamed, and resources inside projects cannot be moved outside of projects. Folders can be made up to three levels deep, and projects can be moved around inside folders as needed.
What this means:
- Permissions assigned at the
organizationlevel descend to everything below regardless offolderandprojectstructure. - Renaming
projectsor moving resources out of aprojectrequires migration of resources, so careful thought to their name and what runs inside them is needed. Foldersare a powerful tool in designing and adapting your IAM permissons hierarchy as needs change.
Consider the following diagram of a GCP Organization:
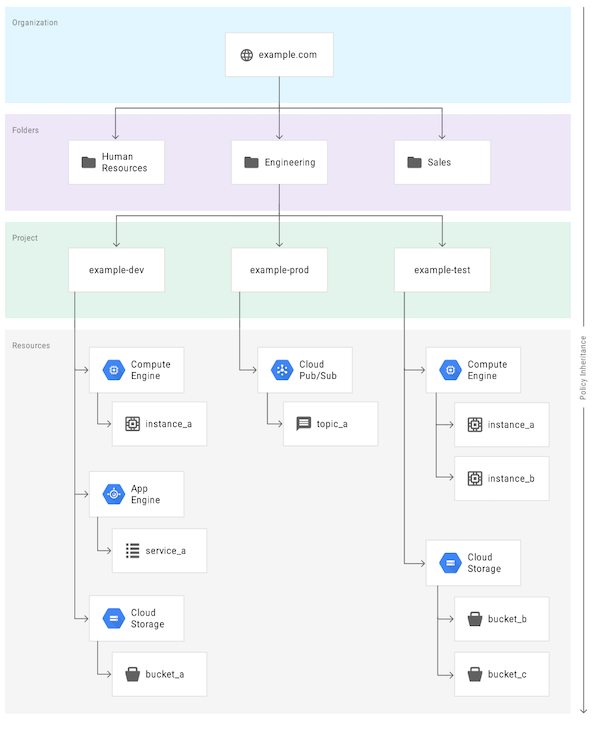
The organization is named example.com, and that is the root of the IAM hierarchy. Skipping over the folders tier for a second -- the projects are organized by operational environment which is very common and a best practice for keeping resources completely separated. Resources in the example-dev project have no access by default to example-test or example-prod. "Fantastic!" you might say, and copy this entire approach.
However, depending on your organization's needs, this hierarchy might not be ideal! Let's break down the potential issues with the folders and the resources inside each project:
- In the
example-devproject,instance_aandservice_amay or may not be part of the same overall "service". If they both operate on data inbucket_a, for example, this makes sense. But ifinstance_ais managed by a separate team and shares nothing withservice_aorbucket_a, you have a permissions scoping and "attack blast radius" problem. Permissions assigned on theexample-devproject might be shared in undesirable ways betweeninstance_aandservice_a. In the event of a security compromise, attackers will be much more likely to obtain credentials with shared permissions and access nearby resources inside that same project. Finally, unless additional measures are taken with custom log sinks, the logs and metrics in Stackdriver will be going to the same project. Administrators and developers of theinstance_aandservice_awould be able to see each other's logs and metrics. - In the
example-testproject, two compute instances and two GCS buckets are in place. Ifbucket_bandbucket_care part of the same overall service, this makes sense. But ifbucket_bserves data with PII in it andbucket_cis where VPC flow logs are stored, this increases the chance of accidental exposure if theStorage ViewerIAM Role is granted at the project level. The service accounts given the ability to read VPC flow logs may be able to read from the PII bucket and vice versa. A simple question to ask is, "If the credentials for this user/group/service account were stolen without us knowing, what would they have access to?" A service account withStorage Viewergranted at theexample-testproject means its credentials, if stolen or misused, would allow viewing the VPC flow logs and PII data in both GCS buckets. - At the
folderandprojectlevel, it may seem reasonable to name the folder after the team name. e.g.team-a-app1-dev. However, in practice, team names and organization charts in the real world tend to change more often than GCP resources. To remain flexible, it's much easier to use GCP groups to combine users into teams and then assign IAM permissions for that group at the desired level. Otherwise, you'll end up havingteam_amanaging theteam_bprojects which will get very confusing. - If your organization becomes large and has lots of geographic regions, a common practice is to have a top-level
folderfor regions likeUS,EU, etc. While this places no technical boundary on where the resources are deployed in descendent projects, it may make compliance auditing more straightforward where data must remain in certain regions or countries. - Certain services, like GCS and Google Container Registry (GCR), don't have very granular IAM permissions available to them unless you want to maintain per-object ACLs. To avoid some of that additional overhead, a common practice is to make dedicated GCP
projectsjust for certain types of common GCS buckets. Similarly, with GCR, container image push/pull permissions are coarse GCS "storage" permissions. Dedicatedprojectsare therefore a near requirement for separate GCR registries. - Highly privileged administrative components that have organization-wide permissions should always be in dedicated
projectsnear the top of theorganization. A common example is theprojectwhere Forseti Security components are installed. If this project was nested inside several levels offolders, an IAM Role granted higher in that structure would unintentially provide access to those systems.
Best Practices¶
- Certain Decisions Have inertia - Some decisions like organization domain name and project names carry a lot of inertia and are hard to change without migrating resources, so it's important to decide on a naming convention for
projectsearly and stick with it. - Consider Central Control of Project Creation - If project creation is to be controlled centrally, you can use an Organization Access Policy to set which group has the
Project CreatorIAM Role. - Avoid Embedding Team Names in GCP Resource Names - Map
folderandprojectnames more closely with service offerings and operational environments. Use groups to establish the concept of "teams" and assign groups the IAM permissions to thefoldersandprojectsthey need. - Use Folder Names at the Top Level Carefully - Consider using high level
foldersto group sub-foldersandprojectsalong boundaries that shouldn't change often but help guide organization and auditing. e.g. Geographic region. - Use separate
projectsfor each operational environment. It's common to append-dev,-test, and-prodto project names and then group them into afoldernamed for thatservice. e.g. The folderb2b-crmholds theprojectsnamedb2b-crm-dev,b2b-crm-test, andb2b-crm-prod.
Resources¶
- Using Resource Hierarchy for Access Control
- Using IAM Securely
- Organization Access Policy
- Forseti Security
Cluster Networking¶
VPC (shared vs peering based on administration model)
Once the GCP organization, folder, and project structure is organized according to the desired hierarchy, the next step is to structure the networking and IP address management to support your use case.
As a small organization, it may make sense to have a single project with a single GKE cluster to start. Inside this project, a VPC network is created, a few subnets are declared, and a GKE cluster is deployed. If another cluster is needed for a completely separate purpose, another project can be created (with another VPC and set of subnets). If these clusters need to communicate privately and avoid egress network charges, a common choice is to use VPC peering which makes a two-way routing path between each VPC (A <-> B). When the third VPC/Cluster comes along, another VPC/Subnet/Cluster is needed. Now, to VPC peer all three VPCs, three total VPC peering connections are needed. A <-> B, B <-> C, and A <-> C. When the fourth cluster is desired, a total of six VPC peering configurations are needed. This becomes difficult to manage correctly and adds to ongoing maintenance costs for troubleshooting and configuration for each additional VPC.
The most common solution to centralizing the management and configuration of VPC networks across multiple projects is the Shared VPC model. One project is defined as the "host" project (where the VPC and Subnets are managed) and other projects are defined as "service" projects (where the services/apps/GKE clusters are deployed). The "service" projects no longer have VPCs and Subnets in them and instead are only allowed to "use" those VPCs/subnets defined in the "host" project. This has a few advantages for security-conscious organizations:
- Using IAM permissions, it's now possible to granularly assign the ability to create projects, attach them to the Shared VPC, create/manage subnets and firewall rules, and the ability to "use" or "attach to" the subnets to different users/groups in each of the "service" projects.
- With centralized control of the networking components, it's easier to manage IP address space, avoid CIDR overlap problems, and maintain consistent and correct configurations.
- Owners of resources in the various "service" projects can simply leverage the networking infrastructure provided to them. In practice, this helps curtail "project-network" sprawl which is very hard to reign in after the fact.
With the organization hierarchy set to have one project for each environment type to separate IAM permissions, a best practice GKE deployment has a GKE cluster for each environment type in its respective project. The natural tendency is to make a Shared VPC for a service offering (e.g. b2b-crm) and attach the three projects for b2b-crm-dev, b2b-crm-test, and b2b-crm-prod to it. From an operational perspective, this might facilitate simpler environment-to-environment communications to move data between clusters or share hybrid/VPN connectivity needs. However, from a security perspective, this is akin to running dev, test, and prod right next to each other on the same shared network. This can unintentionally increase the "blast radius" of an attack as a compromised test cluster would have more possible avenues to pivot and communicate directly with the prod cluster, for instance. While it's possible to do this with sufficient security controls in place, the chance for misconfiguration is much higher.
If the entire point of a Shared VPC is to reduce the number of VPCs to manage, how does that work when each environment and cluster shouldn't share a VPC? One method is to create a Shared VPC for related dev projects and clusters, one for test projects, and one for prod projects and clusters that need to communicate with each other. For instance, a project holding GCE instances sharing a VPC with a project running a GKE cluster as a part of the same total application "stack".
GKE is known for using a large amount of private RFC 1918 IP address space, and for proper operation of routing and interconnectivity features, CIDR ranges should not be reused or overlap.
- Node IPs - Each GKE "node" (GCE instance) needs one IP for administration and control plane communications, and it uses the "primary" range in the subnet declared. If the cluster isn't to grow beyond 250 nodes, this can be a
/24. For ~1000 nodes, a/22is needed. This CIDR range should be unique and not overlap or be reused anywhere. - Pod IPs - By default, each node can run a max of 110 Pods. Each pod needs an IP that is unique, and so GKE slices up
/24CIDR ranges from the "secondary" subnet range to assign to each node. A 250 node cluster will use 250 x/24CIDR blocks. In this case, a/16is needed to handle this cluster (250 x 256 = 64K, closest is 2^8 = 65535). A ~1000 node cluster will need a/14all to itself (1000 x 256 = 256K, closest is 2^18 = 262K). - Cluster/Service IPs - The only CIDR range that can be reused is the Service CIDR. This is because it is never meant to be routed outside the GKE cluster. It's what is assigned to
ClusterIPServiceobjects in Kubernetes which can be used to map friendly, internal DNS names to Pod IPs matching certain labels. A range of/20provides just over 4,090 possible services in a single cluster. This should be more than sufficient for clusters below 500 nodes.
If the prospect of assigning a /16 per cluster has the network team of a large organization nervous, consider using "Flexible Pod CIDR". In many situations, the resources needed by Pods and the size of the GKE Nodes makes the practical limit of pods per node far fewer than the max of 110. If the workloads for a cluster are such that no more than 50-60 pods will ever run on a node, the node will only use a max of half of the /24 CIDR assigned to it. The "wasted" 128 addresses per node can add up quickly. When creating a GKE Node Pool, specifying a MaxPodsPerNode of 64 or fewer will trigger GKE to assign a /25 from the secondary range instead of a /24. The reason for not going to a /26 is because of the natural lifecycle of a Pod IP assignment during a deployment is that greater than 64 IPs might be in use for short periods as some pods are starting while others are still terminating.
Best Practices¶
- Do not overlap CIDRs - In almost every GCP
organization, there exists a need to route to each GKE cluster and between clusters, and the cleanest way to do this with the least amount of engineering is to plan ahead and avoid CIDR overlap. The only known exception is the GKE Service CIDR range. - Use VPC Aliasing - Currently, this is in the process of becoming the default option. Enabling IP aliasing means that the GKE CNI plugin places Pods IPs on an "alias" interface of the underlying node. This reduces latency by reducing network "hops" as the GCP Network infrastructure is used to route Pod-to-Pod traffic and LoadBalancer-to-Pod traffic instead of always involving
kube-proxy. - Consider Using Flexible Pod CIDR - Especially on larger cluster sizes, this can greatly reduce "CIDR waste" and allow for future scaling and expansion of node pools with half or more of the original IP space needed with the default configuration.
- Take Note of Quotas/Limits - When it comes to Shared VPCs, a recent quota/limit on the number of secondary address ranges per VPC went from 5 to 30. This had an effect of limiting the total number of GKE clusters that could be deployed in a Shared VPC as the quotas/limits for the networking components are shared by the "host" project. Large organizations with 1000s of instances will want to be aware of the 15,000 VM per Network when combining large
projectswith large instance counts and GKE node counts.